線性回歸(Linear Regression)
線性回歸(Linear regression)是統計上在找多個自變數(independent variable)和依變數(dependent variable)之間的關係建出來的模型。只有一個自變數和一個依變數的情形稱為簡單線性回歸(Simple linear regression),大於一個自變數的情形稱為多元回歸(multiple regression)。一般回歸分析的介紹都會以簡單線性回歸為例子來說明,在此文章兩種我都會說明和公式推導。
首先先說明一下什麼是自變數(independent variable)和依變數(dependent variable)?
我當初念書的時候第一次接觸的時候一直搞不懂這些專有名詞,尤其配上英文更看不懂,所以我簡單說明一下。
自變數(independent variable): 英文寫independent,中文翻譯叫做「獨立」,所以理論上這個變數是不被其他變數影響的,只會去影響別人,所以被認為是「因」(Cause)
依變數(dependent variable): 英文寫dependent,中文翻譯叫做「相依」,所以這個變數基本上是被其他變數影響的,被認為是「果」(effect)。
所以「因」影響「果」(因→果)
這樣如果還不懂,那白話一點,一個人的「長相」會因為她的「皮膚」、「身材」和「臉蛋」所影響,所以
依變數 (果) :「長相」
自變數 (因) :「皮膚」、「身材」和「臉蛋」。
分析因果關係基本上是資料科學未來的趨勢
之前有個香港的朋友問我「是否能直接用線性回歸看因果關係」嗎?答案是不行
Steven Cheng就是那個香港朋友拉,很優秀,分析速度也快,我只有跟他說用什麼分析、怎麼做和給他一些資料連結,他很快就做出來了。
上面的舉例只是想解釋說那個自變數和依變數有關係
「皮膚」、「身材」和「臉蛋」會影響「長相」→這個例子看起來是因果關係沒錯,我只是想強調自變數和依變數有線性關係,造成誤解,雖然看起來很合理。
我大學老師也是這樣講說自變數是「因」依變數是「果」,但其實這樣解釋是錯的。但還是有人會覺得對阿,這樣是找因果關係阿。
但如果我把依變數(果)換成「身高」,自變數(因)換成「體重」,這時候你會說「體重」去影響「身高」嗎?
還是「身高」會影響「體重」。
所以因果關係的分析,其實不是單純在一個線性回歸就可以找到的。
如果對分析資料科學因果關係有興趣的同學,可以看Granger Causality (GC),但GC是看時間訊號的。
題外話,我博士論文是用Transfer entropy去看訊號之間的因果關係的。
我還沒有研究過非時間訊號,怎麼看因果,但應該跟GC差不多都是看residual,然後算一個F score吧。
這邊大概提一下為什麼看residual,如果「因」會影響「果」,那建出來的模型應該要很好,模型好要怎麼評估→答案是看residual大小吧,residual越小模型越好。所以假設我們要知道「身高」和「體重」哪個是因哪個是果。
應該就建兩個模型
1. 「身高」=a0+a1「體重」+residual_1
2. 「體重」=b0+b1「身高」+residual_2
如果reisual_2<residual_1,代表用「身高去估計體重」會比「體重去估計身高」好
如果我們已經假設這兩個變數有因果關係,但不知道誰影響誰,可以透過上述方式說「身高是因,體重是果」,聽起來很合理吼。
Granger 本人在2003年獲諾貝爾經濟學獎上演說格蘭傑因果關係檢驗的結論只是一種統計估計,不是真正意義上的因果關係,不能作爲肯定或否定因果關係的根據。但卻一堆「很多荒謬論文的出現」(Of course, many ridiculous papers appeared),參考來源維基百科。
GC還是可以拿來做一下因果關係的分析,但在分析結果的解釋上必須小心,因為未知的潛藏因素(在分析時未被量化或是實驗設計未考慮進去的參數)才有可能是因。
比如你看到一個正妹平常都沒有戴眼鏡,今天忽然戴眼鏡了,你會覺得這個妹昨天很晚睡,所以今天沒辦法帶隱形眼鏡。
所以驅使你覺得「戴不戴眼鏡(果)」的是「晚睡(因)」,那是因為你得到的資訊只有「戴眼鏡」和「晚睡」兩種訊息
但背後原因可能是看正妹「延喜攻略」看的太晚,造成她晚睡,所以「延喜攻略」才是真正的因,這原因都可能是當初實驗設計沒有想到或是是無法量化的。
如果你是電視廣告商,你的產品是正妹專用舒眼壓產品,分析目標有客戶群在哪和廣告要下在哪個時段和哪個頻道,以剛剛的例子我們只知道「晚睡」是因,就在晚上各大台都下廣告那費用可觀,且效益不好,因為分析出來的因(晚睡)不是最主要的因,所以如果得知「延喜攻略看的太晚」才是因,這時候廣告商廣告下在晚上時段且是在「延喜攻略」播放的時候和頻道,就可以達到最大收益 → 這個廣告例子是我亂想的。
簡單線性回歸(Simple linear regression)
這邊我就隨便取個例子,假設體脂肪率(依變數)與三頭肌皮褶厚度(自變數)可以用直線關係描述,這邊體脂肪率=y,三頭肌皮褶厚度= x
簡單線性回歸: y=β0+β1x
β0:截距(Intercept),β1:斜率(Slope)為 x變動一個單位y變動的量,如下圖:

回歸分析就只是在找β0和β1,但要怎麼找?
所以要先收集一組資料(xi, yi), i=1, …,n,將每個點都帶到回歸公式內:
ŷi =β0+β1xi,i=1, …,n
ŷi :為預估出來的體脂肪率,和真實資料還是會有誤差(error)或稱為殘差(Residual):
εi = yi — ŷi
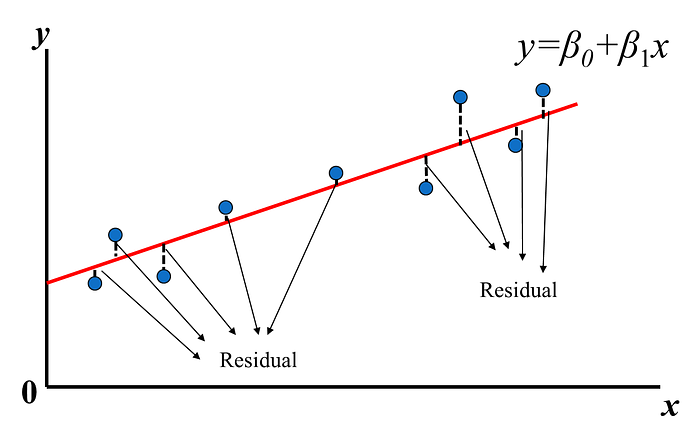
所以回歸分析的目標函數/損失函數(loss function)就是希望找到的模型最終的殘差越小越好,統計上會用一個很專業的名詞: 最小平方法(Least Square)來找參數(β0和β1)。
為什麼叫最小平方法,就是希望誤差的平方越小越好,為什麼是平方,因為誤差值有正有負,取平方後皆為正值,所以我們會很希望所有訓練樣本的誤差平方和(Sum Square error, SSE)接近0。

假設大家懂微積分
為了推估β0,對Loss(β0, β1)做β0偏微分等於0

為了推估β1,對Loss(β0, β1)做β1偏微分等於0
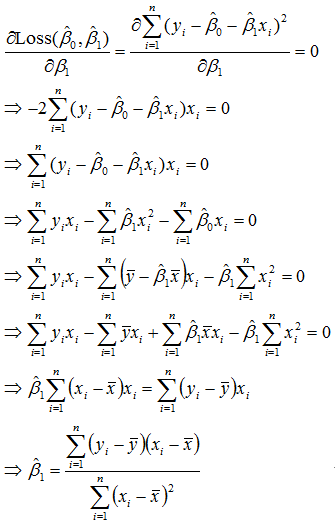
多元回歸(multiple regression)
這邊會寫比較簡短,因為跟前面簡單線性回歸基本上一樣,只是多了幾個自變數,多元回歸開始我會用矩陣的方式來寫推導
這邊我們假設有一組n個資料,d個自變數和一個依變數
這邊有點特殊,X的向量會多一個純量(1)在向量的最前面,這個部分就是在算前面的截距(Intercept)用的。

此時的回歸公式
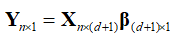
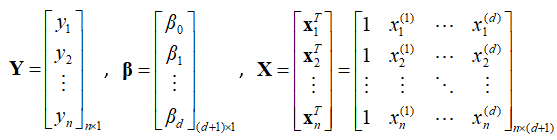
Loss function 定義為
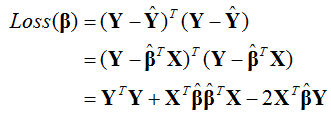
和簡單線性回歸一樣,為了推估β,對Loss(β)做β偏微分等於0
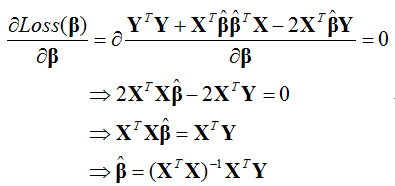
所以多元回歸線的係數跟簡單線性回歸一樣可以求得close form。
但因為這種算法程式計算複雜度很大(算反矩陣),因此可以用隨機梯度下降(Stochastic gradient descent,SGD)來找答案,大家一定很好奇為什麼吧。
我們將一個樣本的多元回歸公式寫出來:
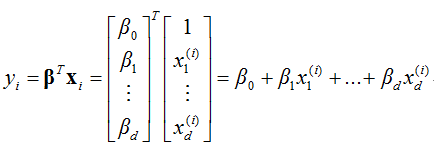
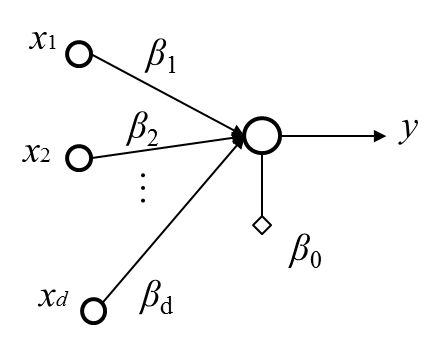
這樣的結構不就等於只有一個只有輸入和輸出層的神經網路,所以可以用SGD去找β的最佳解
以下連結範例是我用TensorFlow用SGD跑回歸的NN和用Close form求解得到的結果,基本上解出來的係數β是一樣的(值差很少)。
