統計學: 常態分布平均數估計與變異量估計以及為什麼樣本變異量分母要減1
3 min readOct 29, 2018
這篇是主要是示範如何估計常態分佈的母體平均數和母體變異量,以及為什麼樣本變異量的分母需要減1。
假設資料分佈是常態分佈,我這利用最大概似估計( maximum likelihood estimation,MLE)進行常態分佈平均數和變異量的參數估計,這邊示範的是單維度估計(多維度作法一樣,但寫法較複雜一點)
假設母體有N個樣本

iid(identical independent distribution)中文叫獨立也同分布。
p(x)是常態分佈(高斯函數)
我們希望最大化概似函數(這邊我先不說為什麼要最大化)
所以公式變成

這邊如果要找平均數(µ)的估計,就針對µ做偏微分 (這時候σ當常數看)

所以平均數的最大概似估計結果如上。
這邊如果要找變異量(σ²)的估計,就針對σ做偏微分 (這時候µ當常數看)

所以變異數的最大概似估計結果如上。這邊的變異量是母體估計,樣本估計會有bias,所以n會-1,這個我先不講為什麼,如果你念統計系,一定聽過自由度,自由度這個講解起來很難理解,我從統計不偏量來推論。
為什麼樣本變異量的分母需要減1
樣本平均數(x^bar)和樣本變異量(s²)

我們來看看樣本平均數的期望值是否跟母體平均數一樣:

由上所以可以得知樣本平均數的期望值跟母體平均數一樣,所以樣本平均數是母體平均數 µ之不偏估計量。
接著我們來看看樣本變異量的期望值(此時樣本變異量分母是n-1)是否跟母體變異量一樣:

這邊要用點小技巧
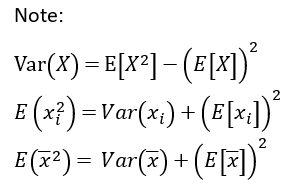
上面很長的公式利用Note的轉換繼續往下推
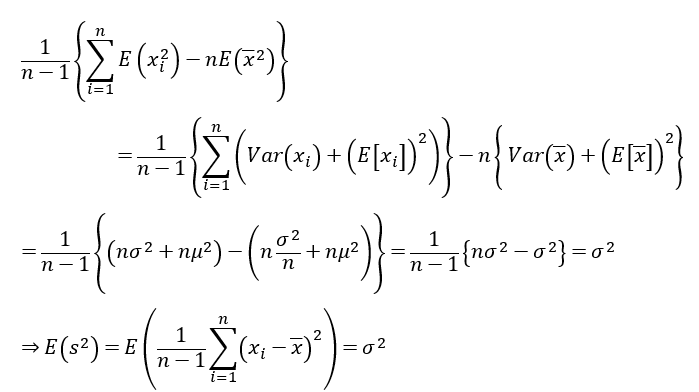
所以樣本變異數分母需要減1,這樣樣本變異量的期望值才會跟母體變異量是一樣的。
這篇是臨時花三十分鐘我重頭慢慢推的(上次推這個應該五六年有了),如果有錯在跟我說一下。
