相關係數與共變異數(Correlation Coefficient and Covariance)
[2019/11/18]相關文章: 「統計學: 皮爾森相關係數為什麼小於等於1」
一般說的相關係數通常是指「皮爾森相關係數(Pearson’s correlation coefficient)」,但當變數之間是順序尺度時用的則是「斯皮爾曼等級相關係數 (Spearman’s rank correlation coefficient)」,這邊重點不是要講當變數是順序尺度時的狀況,所以以下會以連續變數為主。
相關係數很常用在機器學習或是統計分析上使用,主要衡量兩變數間「線性」關聯性的高低程度。
探討兩個變數(或多變數)間是否存在「線性」關係: Correlation Coefficient
將線性關係以方程式表示: Linear Regression
什麼是線性關係和非線性關係?
下圖就是在舉兩個變數(Body fat和triceps skinfold thickness),此兩變數呈現的就是線性關係,也就是兩個變數有高程度的相關,白話一點,三頭肌皮褶厚度越高代表的是體脂肪率越高

下圖舉的例子就是網路抓來的身高和體重的非線性關係。身高和體重的關係是曲線的反應,則是非線性關係,當然這只是一個例子,拋物線關係、S型曲線或是彎彎曲曲的線都算是非線性關係。

皮爾森相關係數(Pearson’s correlation coefficient)
假設有兩個變數(xi, yi), i=1,…,n,一般網路看到的相關係數的公式定義如下:

correlation coefficient(ρ,有的時候會用r來表示)會落在-1到1之間: -1≤ρ≤1,μx和μy 分別代表變數x和y的平均數。
看公式會很沒有感覺,對於懂得人會覺得簡單,對於不懂的人會覺得是天書。
為什麼這樣設計會稱為相關係數勒,其實相關係數公式等於:

這邊共變異數、變異數都是除上(n-1)而不是n的原因是,只用少部分樣本在推論母體時因為偏量(bias)的關係,在推論時樣本推估會少一個自由度(謎之音:這是再說XXX),這不重要想了解網路有很多自由度和為什麼要-1的解釋。
2018/10/29加入文章「統計學: 常態分布平均數估計與變異量估計以及為什麼樣本變異量分母要減1」,這邊有解釋為什麼樣本變異數估計n為什麼要減1。

共變異數(covariance)
我們從公式看,我們將x和y減去各自的平均數後相乘最後算總和,這邊如果我們假設變數x等於變數y時,那這個共變異數不就等於變異數,這時候ρ的值不就等於1,所以x和y就完全相關(x=y)。
所以共變異數其實就等於在算x和y的相關程度,但此時的相關還是相依在x和y的尺度上,好饒舌唷,什麼意思哩。
假設x變數是身高(單位:公分),y變數是體重(單位:公斤),x的標準差計算出的單位是公分,y的標準差計算出的單位是公斤。那共變異數算出來的單位是什麼呢?答案是「公分*公斤」。
所以今天如果是比較「身高和體重」的相關度高,還是「身高和年齡」的相關度高,如果只看共變異數就是在一個不同單位下比較的方法,很不公平。
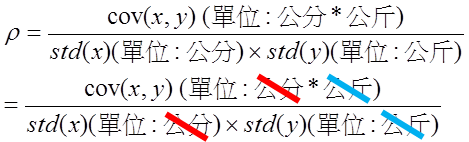
所以在共變異數我們會除上兩個變數間的標準差,如此一來單位也都被消除了,大家都回到同一個基準線上,值會落在正負1之間。
(這個是我自己念書感受出來的解釋方式,不代表數學上這樣解釋是合理的,但我個人認為比較好理解)
相關係數實際計算方式如下,我這邊舉了五個點的例子,分別為(x, y)={(1,4), (2,5), (5,10), (6,12), (7,15)}。
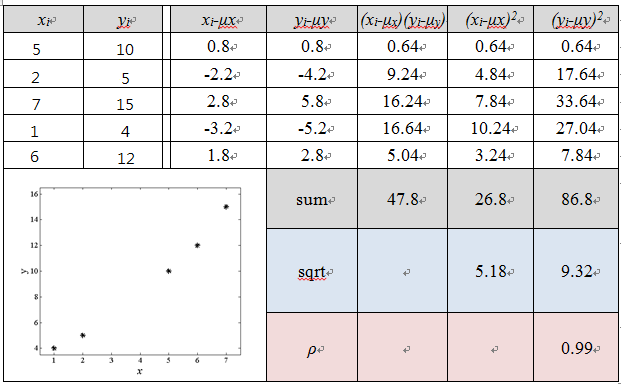
下圖示說明不同範圍內的ρ值呈現出來的結果。

