深度學習系列: 什麼是AP/mAP?
一般深度學習看到的指標都是寫AP,AP就是average precision。但文章內很常看到的指標有兩個分別為precision和recall,一般文章大多只看precision,但有時候precision並沒有增加太多時,作者通常就是提出他在recall也有大幅提升,這章節就是要介紹「什麼是precision」和「什麼是recall」,和「什麼是AP」(其實以前文章「機器學習\統計方法: 模型評估-驗證指標(validation index)」有介紹過一些,但那篇是所有評估指標的介紹太繁瑣)。
Note: 最後有附上IOU (intersection over union)怎麼計算的。
「什麼是precision」和「什麼是recall」
下圖是我從「機器學習\統計方法: 模型評估-驗證指標(validation index)」那篇文章節錄過來的。

Precision: 「所有被檢測為目標」但「正確分類為目標」的比例。
Recall: 資料中的「所有目標」但「正確分類為目標」的比例。
比如說: 有個分類問題要分「狗」和「不是狗」
Precision:
所有被檢測為目標=所有被模型判斷為狗的個數
=是狗且被模型判斷為狗的個數(TP) + 不是狗且被模型判斷為狗的個數(FP)
Recall:
資料中的所有目標=資料中為狗的個數
=是狗且被模型判斷為狗的個數(TP) + 是狗但被模型判斷為不是狗的個數(FN)

「什麼是AP」
前面介紹了precision和recall,那這邊介紹的AP是什麼?
這個名詞比較常用在目標偵測(object detection)的評估指標中,AP就是average precision,多了一個average,為什麼多了average?
在目標檢測中,我們通常會認為預測的目標(通常是一個四四方方的bounding box)和Ground truth進行IoU計算,如果IoU大於一個閾值(threshold,通常是0.5),則認為這個目標被是一個TP,如果小於這個閾值就是一個FP。 (文章最後面有IoU的計算方式,就可以看到bounding box長怎樣了)。
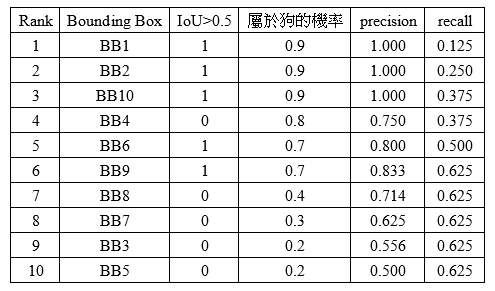
AP計算用舉例的可能會方便一點,下表為例子,這邊是舉「狗偵測」。
假設真實情況有8隻狗(GT1~GT8)。
Bounding box是模型偵測出來的有10個狗(BB1~BB10)。
有些BBox只偵測到狗的腳或頭,所以IoU很低(比如BB3, BB4, BB5, BB7, BB8),然後GT6和GT7沒偵測到(FN=(GT7, GT8))。

假設IoU>=0.5,我們才會說他有正確判斷為狗(下表第二欄)
TP=(BB1, BB2, BB6, BB9, BB10)
FP=(BB3, BB4, BB5, BB7, BB8)

這時候根據模型說「判斷為狗的機率」(網路範例大多用Confidence表示)進行排序。

根據不同rank下去計算precision和recall。
Rank 1:
Precision = (>=Rank 1被判斷為狗的個數) / (>=Rank 1的總個數)=1/1=1
Recall = (>=Rank 1被判斷為狗的個數) / (真的為狗的總個數)=1/8=0.125
Rank 2:
Precision = (>=Rank 2被判斷為狗的個數) / (>=Rank 2的總個數)=2/2=1
Recall = (>=Rank 2被判斷為狗的個數) / (真的為狗的總個數)=2/8=0.25
Rank 3:
Precision = (>=Rank 3被判斷為狗的個數) / (>=Rank 3的總個數)=3/3=1
Recall = (>=Rank 3被判斷為狗的個數) / (真的為狗的總個數)=3/8=0.375
Rank 4:
Precision = (>=Rank 4被判斷為狗的個數) / (>=Rank 4的總個數)=3/4=0.75
Recall = (>=Rank 4被判斷為狗的個數) / (真的為狗的總個數)=3/8=0.375
Rank 5:
Precision = (>=Rank 5被判斷為狗的個數) / (>=Rank 5的總個數)=4/5=0.8
Recall = (>=Rank 5被判斷為狗的個數) / (真的為狗的總個數)=4/8=0.5
Rank 6:
Precision = (>=Rank 6被判斷為狗的個數) / (>=Rank 6的總個數)=5/6=0.833
Recall = (>=Rank 6被判斷為狗的個數) / (真的為狗的總個數)=5/8=0.625
Rank 7:
Precision = (>=Rank 7被判斷為狗的個數) / (>=Rank 7的總個數)=5/7=0.714
Recall = (>=Rank 7被判斷為狗的個數) / (真的為狗的總個數)=5/8=0.625
Rank 8:
Precision = (>=Rank 8被判斷為狗的個數) / (>=Rank 8的總個數)=5/8=0.625
Recall = (>=Rank 8被判斷為狗的個數) / (真的為狗的總個數)=5/8=0.625
Rank 9:
Precision = (>=Rank 9被判斷為狗的個數) / (>=Rank 9的總個數)=5/9=0.556
Recall = (>=Rank 9被判斷為狗的個數) / (真的為狗的總個數)=5/8=0.625
Rank 10:
Precision = (>=Rank 10被判斷為狗的個數) / (>=Rank 10的總個數)=5/10=0.5
Recall = (>=Rank 10被判斷為狗的個數) / (真的為狗的總個數)=5/8=0.625
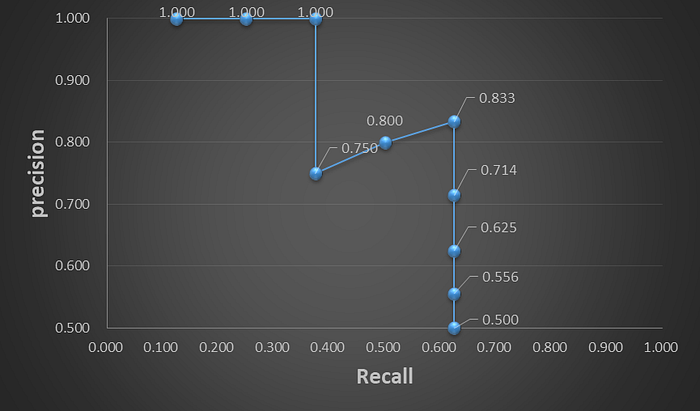
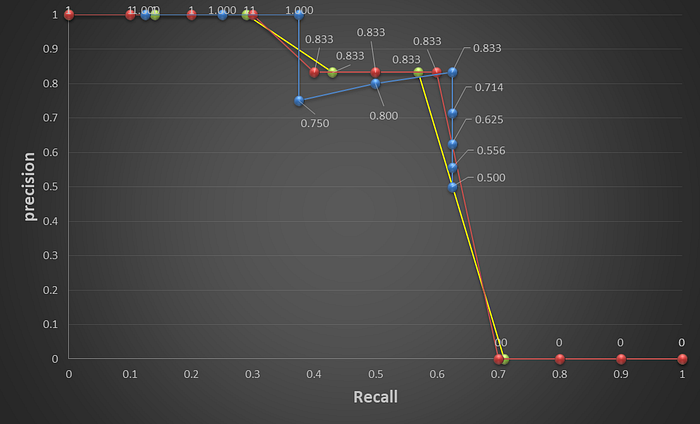
所以AP就是計算這條precision-recall curve下的面積(area under curve, AUC)。
AP (Average Precision) in PASCAL VOC challenge
VOC 2010之前的方法在算AP部分時會做一個小轉換。
就是選取Recall>=0, 0.1, 0.2,…, 1,這11的地方的Precision的最大值。
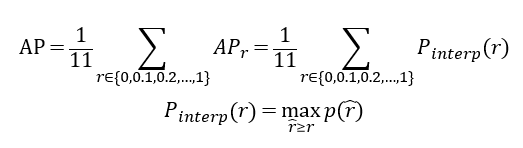
這邊的p等於precision,r={0, 0.1,…, 1}
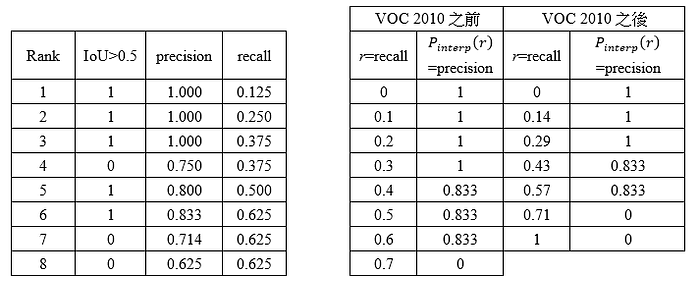
VOC 2010之後的方法在recall的決斷值又做了修正,就是選取Recall>=0, 0.14, 0.29, 0.43, 0.57, 0.71, 1,這7的地方的Precision的最大值。

下圖表為轉兩個方法換後的結果。
此例子VOC 2010之前的AP=(1+1+1+1+0.833+0.833+0.833+0+0+0+0)/11=6.433/11= 0.591
此例子VOC 2010之後的AP=(1+1+1+0.833+0.833+0+0)/7=4.666/7= 0.667
感謝David哥找到上一行公式計算有錯誤的地方
COCO 資料庫的mAP
COCO 資料庫的AP計算比較特殊。
論文常常看到AP[.50:.05:.95](論文寫法可能不一樣,但意思是一樣的)
這個解讀方式是在COCO資料庫對performance評比時,IoU閾值設定是動態的,一般VOC資料庫IoU閾值設定為0.5。

AP說完了,來說mAP吧。
mAP更簡單,我剛舉例是只舉一個狗的判斷,但物體偵測不可能只偵測一種東西,在COCO資料庫有80種。所以mAP就是每一種物體的AP算完後的平均值。
IOU (intersection over union)
IOU(有些文章會用IoU,o用小寫原因是over是介詞不太重要用小寫,但其實沒差看得懂定義好就好)計算方式非常簡單,白話說就是兩個物件的重疊(overlap)/交集比例,從下公式和下圖可以明顯得知,
IOU就是「兩個物件的交集」除上「兩個物件的聯集」。

