機器/統計學習: 羅吉斯回歸(Logistic regression)
線性回歸Review:
這邊假設有d個維度的資料 (統計上會說有d個隨機變量), β是回歸係數(參數)。這邊的符號後面會一直沿用。

這篇是介紹羅吉斯回歸(Logistic regression),羅吉斯回歸(Logistic regression)不同於線性回歸(Linear regression)
線性回歸是用來預測一個連續的值,羅吉斯回歸是用來分類。

從圖上來看,線性回歸跟羅吉斯回歸公式是一樣的
線性回歸輸出是一個連續的實數,但羅吉斯回歸就是用線性回歸的輸出來判斷這個資料屬不屬於target(二分類問題: target和non-target),但羅吉斯回歸要怎麼做分類?
一個最簡單的概念,將點帶進去回歸線,回歸線輸出值若是>=0,是一類(target),值<0是另一類(non-target),超簡單的吧。

這個判斷法其實就是一個unit-step function,如下

這種輸出很直覺也很直接,但演算法開發很不喜歡這樣的東西,因為太絕對了,越靠近0的位置,理論上越容易分類錯誤,所以這時候我們加上一個對數函數,這時候這個輸出就更有彈性。
羅吉斯回歸用到的對數函數是Sigmoid函數,如下(這邊寫的Sigmoid是兩個簡易版,因為網路這兩種寫法都有人寫,所以我都列出來,當然還有複雜版,谷哥一下會找到Sigmoid還有平移和放大縮小的參數):


綜合上述,羅吉斯回歸公式其實就是(這邊我用多變量的來寫)

要怎麼找(求解)羅吉斯回歸參數(β)?
線性回歸是預測一個數字,所以我們會希望這個預測值和目標值越接近越好,所以可以利用最小化平均絕對誤差(Mean Absolute Error, MAE)或是平均平方誤差(Mean Square Error, MSE)來求解。
但不同於線性回歸,羅吉斯回歸是用來做分類的,所以不能像線性回歸的方式(ex: 最小平方法)求解,分類問題在參數型學習(parameter learning)通常都是用最大概似函數估計法 (Maximum Likelihood Estimation, MLE)求解,當然羅吉斯回歸也是,但這邊衍生出一個問題,最大概似函數估計法是估計某一個函數的最大概似量,羅吉斯回歸是哪種函數?
如果有修過初等統計學應該知道有個鬼東西叫做伯努利分布(Bernoulli distribution)(大學的時候都會戲稱唸完這個就真的白努力了),伯努利分布的機率密度函數(probability density function, pdf):

所以這個函數就是當試驗成功時,柏努利的隨機便量等於1(x=1),反之試驗失敗柏努利的隨機便量等於0(x=0)。
這跟上面羅吉斯回歸有什麼關係?
回到羅吉斯回歸的目標,主要是做二分類問題,這時候羅吉斯回歸的輸出有兩個,target和non-target機率(也有人說是positive and negative的機率),但機率的輸出最後還是要判斷是不是target(y=1是target,y=0是non-target)
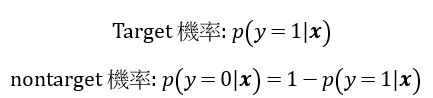
跟伯努利分布是一樣的,所以羅吉斯回歸的概似函數就是取伯努利分布的機率密度函數。
這邊不講最大概似函數估計法的細節,網路上應該也很多範例。
我們開始用「最大概似函數估計法」和「伯努利分布的機率密度函數」對羅吉斯回歸做參數估計。
假設我們有n組資料,概似函數為
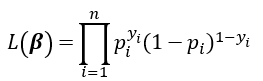
為了簡化針對概似函數取-log,因為取負號所以最大化概似函數變成最小化對數概似函數,在機器學習稱這個為logloss)
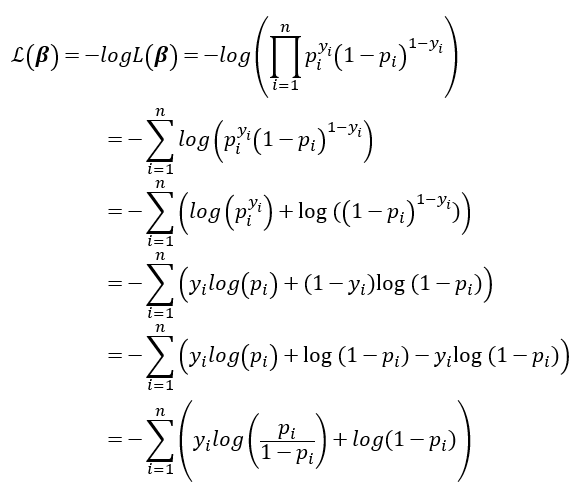
對應一下羅吉斯回歸(怕看的人忘了pi是什麼)
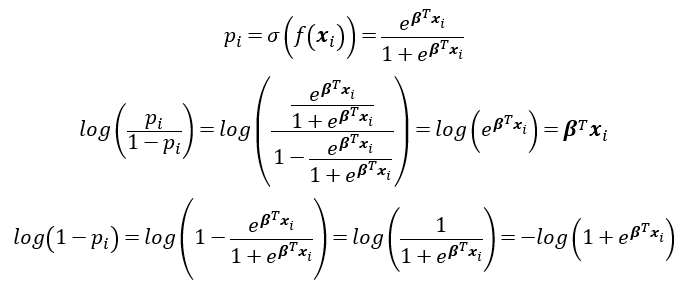
所以logloss在簡化一下
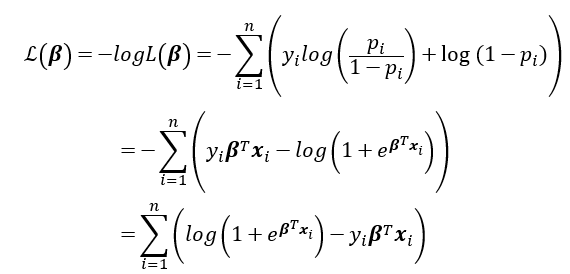
簡化好了,就來找解的精隨(可以看基礎數學二那篇文章),梯度法(偏微分)
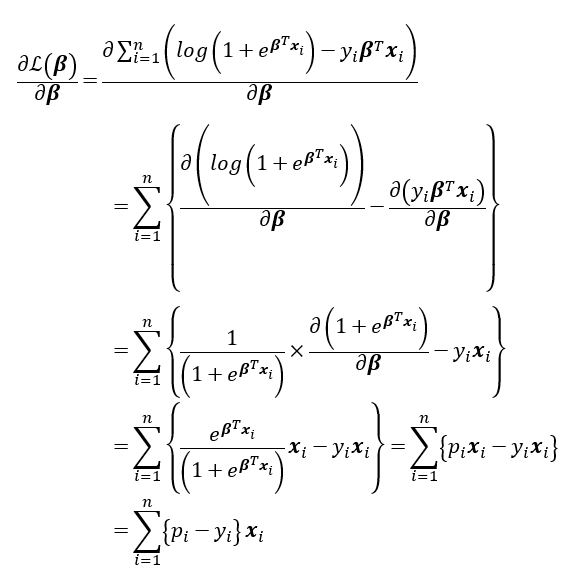
寫成梯度求解如下:
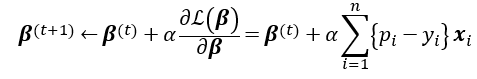
α為學習率。
羅吉斯回歸推導結束,慢慢看應該看得懂,不難。
Note:
這邊大概提一下,我這邊用β當參數,但有些文章會寫W,原因是統計學上習慣用β來表示coefficient,在機器學習上習慣用W來表示coefficient,但大同小異。
另外,我把截距(intercept)包到x向量內了,所以不同於一些文章會額外推估截距的導數,這篇文章的截距估計跟回歸係數同時一起推導了。
