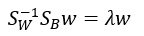機器學習: 降維(Dimension Reduction)- 線性區別分析( Linear Discriminant Analysis)
線性區別分析(Linear Discriminant Analysis,LDA)是一種supervised learning,這個方法名稱會讓很人confuse,因為有些人拿來做降維(dimension reduction),有些人拿來做分類(Classification)。如果用來做降維,此方法LDA會有個別稱區別分析特徵萃取(Discriminant Analysis Feature Extraction, DAFE),多個名字也比較好區隔。
此篇主要是要講降維(dimension reduction)部份。如果有看過PCA的介紹,再來看這篇會比較有感覺,也比較容易上手。
在降維度的方法上,LDA是PCA延伸的一種方法,怎麼說哩。PCA目標是希望找到投影軸讓資料投影下去後分散量最大化,但PCA不需要知道資料的類別。而LDA也是希望資料投影下去後分散量最大,但不同的是這個分散量是希望「不同類別之間的分散量」越大越好。所以LDA和PCA差異的部份,PCA是無監督式(unsupervised learning)方法,LDA多了這四個字(「不同類別」)是一種監督式(supervised learning)方法。
LDA怎麼實現投影後不同組之間的分散量越大越好?
第一個要先定義什麼是分散量,如果有看過PCA的介紹,應該對於我們提到希望投影後變異量最大化這件事情比較熟悉,PCA所謂的變異量在這邊指的就是在敘述資料的分散量。
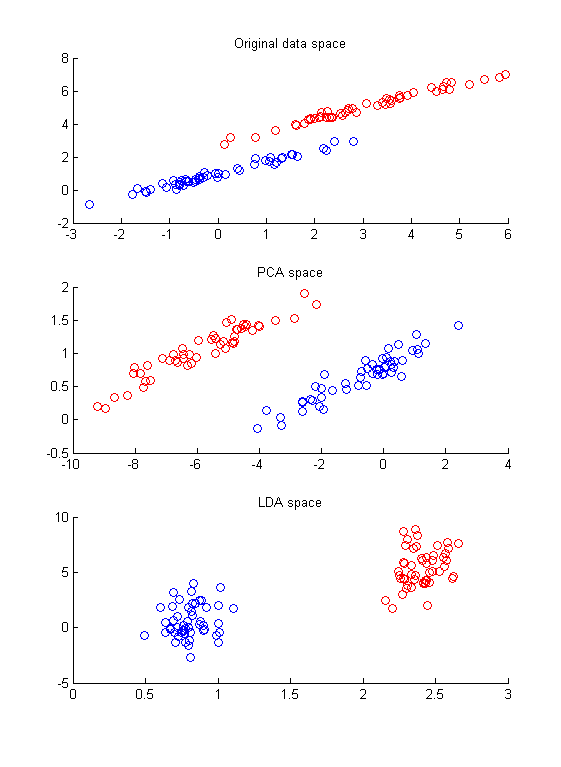
此篇文章我會一直用下圖當作範例
如果我們用PCA的方式,得到的投影軸是紅色的線(投影後變異量最大)。

但如果我們的資料中有類別(監督式)的資訊了,就要好好拿來應用阿。
下圖為上圖加上「類別」的資料

這時候如果還是用PCA得到的投影軸對最後的分類問題能達到最大的幫助嗎?
但在LDA因為我們有了資料類別的訊息,所以可以把類別訊息考慮進算法內。LDA部份則是希望類別跟類別之間的區別性越開越好,這是什麼意思哩? 就是投影後紅的點跟藍色的點能越「區隔」開越好,最理想狀態是投影後用一個閾值(圖中的decision line)就可以區隔兩類,所以這個方法叫做「線性區別分析」(下圖)。

我這邊先把LDA和PCA執行這筆資料的結果呈現出來。
PCA部份,紅色線是PCA找到最大主成分,藍色是PCA找到次大的主成分,然後有相對應的直方圖,是不同成分下,資料投影到投影軸後的直方圖,如果投影後的資料可以區隔開的話,從直方圖可以很明顯看到會有兩個分佈。從PCA投影的資料很難看到只用一個成份可以完美區隔兩類。

LDA部份,紅色線是LDA找到最大成分,藍色是LDA找到次大的成分,然後有投影到投影軸後的直方圖。從LDA投影的資料,可以清楚看到只需要最大的成分(紅色投影軸)就可以完美區隔兩類。
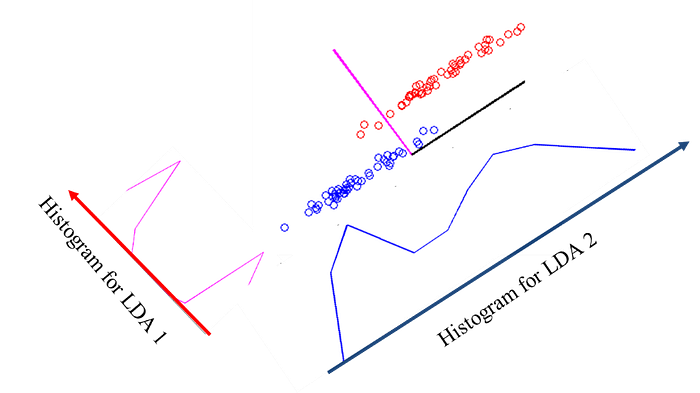
這邊我會把兩種方法投影後的資料一起呈現出來在下圖,所以可以清楚看到,LDA的執行效果比PCA好。→這句話是廢話,因為監督式學習基本上都會比非監督式學習好,前提是兩種方法的假設是差不多的情況。
LDA演算推論(一)
LDA的方法算式統計參數型的監督式學習,什麼叫統計參數型?就是需要去估計統計的一些變量,比如說平均數和變異數等,這邊很直覺因為我剛剛說了分散量是靠變異量來的。那還是不知道要怎麼達成LDA阿。
LDA希望投影後的資料,組內分散量(within-class scatter)越小越好,組間分散量(between-class scatter)越大越好。
所以要先定義什麼叫做「投影後的資料」、「組內分散量(within-class scatter)」和「組間分散量(between-class scatter)」。
假設有一組n個樣本有L類別的資料{(x1, y1), (x2, y2),…, (xn, yn)},xi∈Rd,yi∈{1,2,…,L},投影軸為w,所以投影後的點為{wT x1, wT x2,…, wT xn}

投影後的資料: 可以參考PCA那邊,有比較詳細的說明。
組內分散量(within-class scatter)
組內分散量很容易理解就是看自己組內的資料變異量是什麼。
第j類分散量(共變異數矩陣也以參考PCA那邊,有比較詳細的說明)
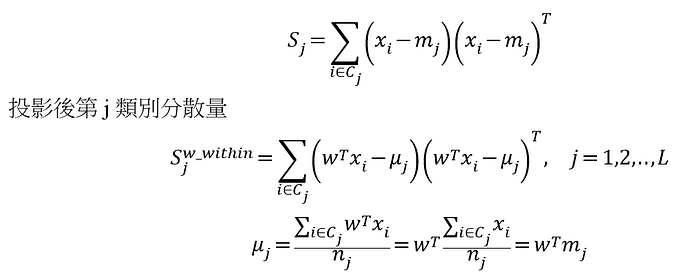
μj:投影後的資料第j類別的平均值, mj:原始資料第j類別的平均值, nj:第j類別的樣本數
投影後每一類別分散量和原始每一類別分散量關係如下:

組內分散矩陣(within-class scatter)就是把每一個類別的分散量加起來
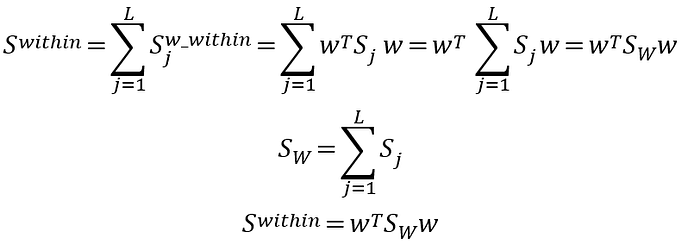
到這邊應該算很簡單吧!
組間分散量(between-class scatter)
組間分散量比較沒這麼好理解,為什麼哩,第一個組間怎麼定義,第二個組間分散量是什麼?
組間定義最直覺就是類別跟類別之間群心(類別的平均)的差異,所以組間分散量就是群心跟群心之間的變異量。
原始資料第i類別的分散量 (第i類組別群心和其他類別群心的變異量和)
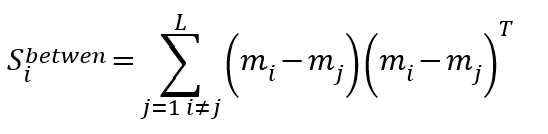
投影後第i類別組間的分散量
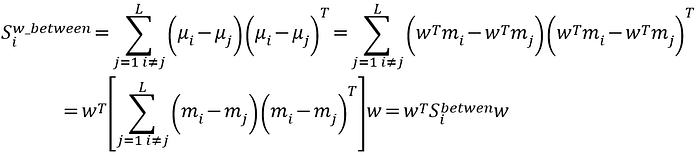
組間分散矩陣 (between-class scatter)就是把每一個類別的分散量加起來
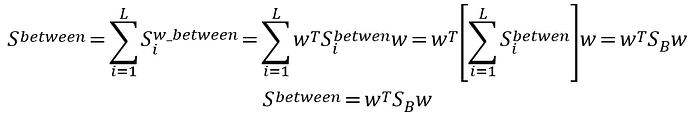
到這邊可能需要消化一下。
所以到這邊我們知道了「投影後的資料」、「組內分散矩陣(within-class scatter)」和「組間分散矩陣(between-class scatter)」的算法。
LDA演算推論(二)
這邊組內分散矩陣和組間分散矩陣還是分開的兩個東西,要怎麼達到LDA的目的(「不同類別之間的分散量」最大化),記得一個要訣「組內差異小,組間差異大」,在LDA必須藉由費雪準則(Fisher criterion)達到這個目的。費雪準則定義了組間和組內分佈的分散量是藉由組間和組內變異量的比值去計算的。

當然這只是費雪準則的一種,費雪準則還有取trace後的值來計算的,這邊不討論,我們純粹看矩陣狀態下的費雪準則。
看到這邊有沒有覺得哪裡怪怪的。 S_within是矩陣為什麼可以放在分母?但因為我這邊是先寫通用情形,所以這邊先寫成相除的形式,但實際應該是
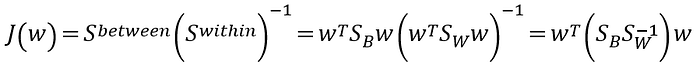
通常組內散布矩陣(Sw),在不造成混淆的情況下, 是一個對稱半正定矩陣。如果樣本數大於資料的維度數,Sw通常是正定矩陣,也就是可逆矩陣,所以基本上inverse存在。但Sw也有出包(singular case)的時候,這時候就需要將組內散布矩陣進行正規化,這邊不探討。
到這邊還是不知道LDA要怎麼找出投影矩陣w,所以回到我們的問題,我們希望組內差異小,組間差異大,J(w)分子是組間(假設越大越好),分母是組間(越小越好),所以我們是希望J(w)越大越好。
所以又回到最佳化問題
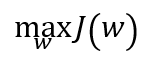
但是沒有限制式,這個問題又解不出來,不信你去試看看。
但上述問題會等價於
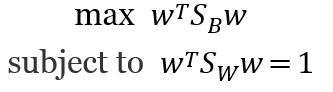
所以可以用 Lagrange來解
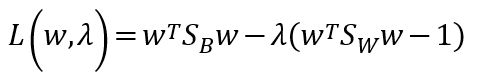
λ: Lagrange multiplier.

看到這邊有沒有覺得挖靠,LDA就只是在解inv(Sw)*SB的eigenvalue(λ)和eigenvector(w)