機器學習-支撐向量機(support vector machine, SVM)詳細推導
Note: 我這篇沒有寫到SVM怎麼用kernel trick處理非線性問題,相關kernel內容可以看「機器學習: Kernel 函數」,兩篇內容稍微整合理解一下,應該很容易做到kernel SVM的推導。
SVM是一種監督式的學習方法,用統計風險最小化的原則來估計一個分類的超平面(hyperplane),其基礎的概念非常簡單,就是找到一個決策邊界(decision boundary)讓兩類之間的邊界(margins)最大化,使其可以完美區隔開來。
以下用一個例子來說明要「如何只用身高體重就來判斷是男生還是女生」。e.g. 分類男生和女生兩類,特徵資料只有「身高」和「體重」。
這邊我先隨便舉男生有10組資料,女生也是10組資料。

所有分類的問題都是在找下圖紅色那條分類的線
不一定是直線,有可能是曲線,本範例只會提到直線部分,不同的演算法都是在不同的假設或是條件下去找那條分類的線。

比如說高斯分類器就是在利用兩組資料的高斯機率分布/高斯概似函數(Gaussian likelihood function),去判斷誰的後驗機率(posteriori probability)/概似函數值較大,就判給哪一類別。
SVM則是去假設有一個hyperplane(wTx+b=0)可以完美分割兩組資料,所以SVM就是在找參數(w和b) 讓兩組之間的距離最大化。
SVM數學式子
假設訓練資料為

以剛剛範例為例,這邊的

在此我們先不考慮有「資料混在一起」的問題,也就是所以所有的資料都可以被完美分類(hard-margin SVM)。
因此數學將此必須滿足條件寫出來則是

所以SVM在找Optimal hyperplane就是希望區隔兩類之間的邊界(2/|w|)可以越大越好。

所以SVM的求解本身就是一個簡單的最佳化問題(在一些條件下,希望兩類的邊界距離越大越好),轉換成數學公式如下:

(如果有修過最佳化理論的人,針對上式子應該很有感觸,上了一學期的課程終於知道最佳化理論用在哪裡了。)
當然真實的資料不太可能有可以完美分類的案子,因此我們在training 的時候可以容忍一些data落到邊界之內(下圖範例),此類的SVM稱為soft-margin SVM。
因為hard-margin SVM推導跟soft-margin SVM推導差不多,所以以下都會以soft-margin SVM為推導範例。至於SVM的強大是因為kernel function的關係,讓SVM可以從線性分類轉換到非線性分類上,但因為本文章偏重在SVM本身的推導,所以kernel method則不會在此說明。

在soft-margin SVM計算中,soft-margin SVM是如何容忍一些data落到邊界之內呢?


PS: 落在邊界上的樣本(在容忍邊界內的樣本)稱為Support vectors,因此此方法被稱為Support vector machine。
但因為這個slack variable是用在限制式內,所以在目標函數也需要考慮進去,因此將所有點的slack variable相加並且給予一個權重/懲罰參數(C,要為正值的實數),用來調整slack variable在目標函數的重要性。
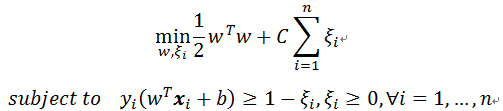
因為未知參數在限制式內,無法直接去解此最佳化問題,因此在解「 有條件的最佳化問題」時,有時需要把原本的問題轉換成對偶問題(Dual Problem)後,會比較好解。
因此我們用Lagrangian dual function (因為有兩種限制式所以Lagrangian parameters為αi>=0和βi>=0)將原最佳化問題轉換成Lagrangian函式:

根據Karush-Kuhn and Tucker (KKT) condition的理論,如果我們要得到參數的最佳解,則直接將Lagrangian函式偏微分該參數,因此(詳細推導請看最後註解)
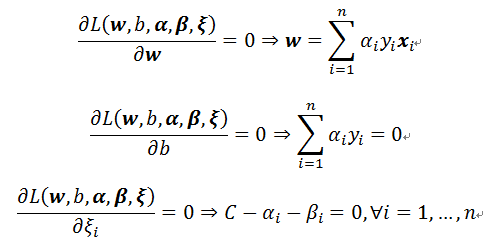
根據Lagrangian求得的解,我們將最佳化問題做個轉換(推導部分看註解):
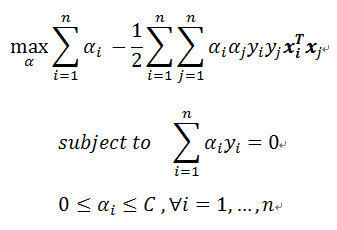
到這邊看得懂的人應該知道這個問題是已經轉換成二次式(Quadratic Programming)去求解,看不懂的人到這邊應該還是看不懂。
Quadratic Programming簡單回顧
二次式(Quadratic Programming)的精神是要將函數呈現成下式:

H是Hessian matrix,為對稱矩陣
根據不同的參數特性,可以得到對問題不同的結論
· 如果H是半正定矩陣,那麼f(x)是一個凸函數。
· 如果H是正定矩陣,那麼全局最小值就是唯一的。
· 如果H=0,二次規劃問題就變成線性規劃問題。
如果有至少一個向量x滿足約束而且f(x)在可行域有下界,二次規劃問題就有一個全局最小值x。
所以SVM最後其實只是一個二次式求解問題,整理後如下列方程式:


結論
SVM其實只是一個二次方程式求解的問題,只是中間有很多小技巧,基本上有些先修知識要有,比如微積分(所有機器學習都會用到)、線性代數(所有機器學習都會用到)、最佳化理論等。
從最後導出的公式可以得知,SVM只是在解所有的αi,如果你很有感覺你會發現最後其實只有support vectors的αi會>0,其他的training 樣本αi=0。所以是不是support vector的判斷就是看相對應解出來的αi。
註解:



